
Building a Serverless Podcast Workflow: Adventures with AI
As you may know, I’m a co-host & standing guest on the Logicast AWS News Podcast, where we discuss all things in the news about AWS.
What you probably don’t know, is that the preparation & production of a podcast is rather a lot a work, and that anything to speed up & simplify the process is absolutely necessary – especially for a weekly podcast.
On the preparation side, being about recent AWS news helps because we don’t have to do as much work on research side – we just turn up & record. This doesn’t help us on the production side though, which is still a lot of work.
To give you a flavour, the things we have to do every week are:
- Pick the articles (and ideally read them)
- Share with the guest and answer any questions they might have
- Record the episode
- Download the files
- Convert the files into the correct formats
- Create a trailer
- Create a summary (the “show notes”, in podcasting parlance)
- Upload to the publishing platform
- Social promotion
On top of this, because “content is king”, we want to be able to re-use the episode as much as possible. Our current wishlist is:
- Create short “clips” for social posting to “drip feed” the content and drive subscribers
- Create a long-form blog post from the recording, that isn’t just a transcript
- Add full subtitles to each video.
As with any problem, there were a few options to solve both the required tasks, and start on the wishlist.
Option 1: Outsource it.
This looks like a combination of things, from hiring a production & marketing person (much love to Alicja for the work she does), to using 3rd party tools to help with some of the creation (I’m not linking the tool, because they’re not paying us, but we use an AI service for clip/trailer creation)
Option 2: Automate All The Things
Obviously I want to do this, because I’m an engineer, and in my head my time is free. I’m sure Logicata disagrees with me here though…..
However, throw in the fact that we “needed” a reason to talk about AI, we thought we’d better have a go at doing “something”.
Enter the Workflow
Now, I’m a Serverless AWS Community Builder, so obviously I went straight for Lambda & Step Functions here. I started playing around with options, and for once, doing some research. I know! Didn’t see that coming either.
Up in this rarified research-fueled air, I found this AWS blog: https://aws.amazon.com/blogs/machine-learning/create-summaries-of-recordings-using-generative-ai-with-amazon-bedrock-and-amazon-transcribe/
This was a really good foundation for what we needed/wanted to build, it even had a sample project at the time which let me short-circuit hours of dev time
After a bit of tweaking, I came up with this:
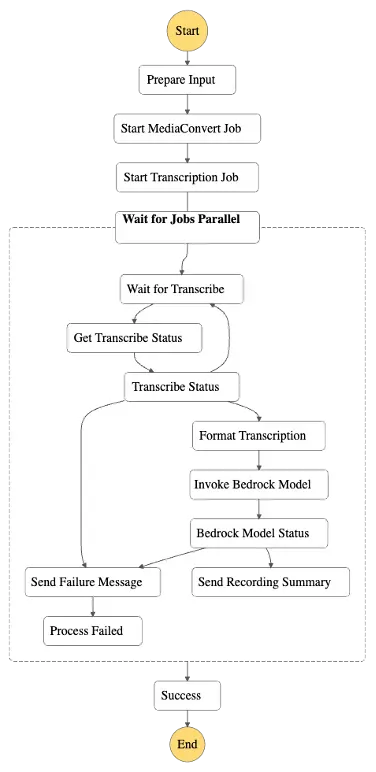
Serverless AI Workflow V1
Yes, that’s a big scary image, so let’s break it down.
The process is:
Step 1: Kick-off with File Upload
We start by uploading an m4a file to an S3 bucket, and use the bucket notification to trigger the workflow.
I have to download the files from the recording platform, which isn’t a problem, but is a bit annoying.
Step 2: Media Conversion
AWS Elemental MediaConvert transforms the m4a file into an mp3 format, ready for Spotify and other platforms.
We have to do this because the recording platform delivers an m4a, but most audio platforms prefer an mp3.
This is a fire-and-forget approach, so I’m manually checking for the job completion and downloading the file afterwards. Again, not a problem but somewhat annoying.
Step 3: Transcription
Amazon Transcribe converts audio into a text-based JSON document. This is actually the most expensive part of the process, which I didn’t expect at the outset.
Step 4: Run the prompts
Amazon Bedrock reads the transcription and generates summaries and titles using prompts stored in DynamoDB.
Since building this, prompt manager became a thing, because as everyone knows the best way to get AWS to create a new feature is to build it yourself first.
This is all in one Lambda, using a loop in Python. I regret this enormously but it was the quickest option.
Step 5: Outputs
The final outputs are sent to an SNS topic for easy access.
We have a Slack channel email subscribed to the topic, so the messages aren’t lost in inboxes.
We went with SNS & email both because the baseline I used was already doing it, and I couldn’t be bothered to work out the schema for AWS Chatbot. I should probably do this though.
Obviously this isn’t our full wishlist, or even the complete set of required tasks. However, with careful prompting, it does make the required tasks a lot faster to do. The summary is a good prompt to create the show notes & the LLM creates the title – sometimes we use it, sometimes not.
There must be some problems though?
You would be correct there. The issue comes back to my time – it’s only free in my head. Turns out, building this sort of thing takes rather a lot of time & effort, so it has a number of “rough edges”.
Chiefly:
1. It’s really fragile.
Seriously, one dodgy prompt, or an episode that runs a touch long, bang. All falls over, nothing comes out the end. Lately we’ve been hitting rate limits too, presumably because we’re on an ancient version of Claude.
This is mostly because I’m hacking it together, and not spending a proper amount of time on it
2. Transcription is expensive, and the workflow must restart on error.
Again, because it’s fragile, the re-runs have to start at the beginning. What’s worse, because most of the failures are prompt-based and errors in the model invocation are only checked after-the-fact in a downstream task, I can’t take the offending prompt out and re-drive from the failure, thus forcing a full re-run.
3. It’s kinda slow
Nothing doing here, it’s just slow. No parallelisation of the prompts (due to the aforementioned bad Python loop), and a single lambda taking every output response and dumping it onto SNS at the same time.
Improvements.
OK, we’ve run this for a few months (eek), and I’ve even delivered a whole talk on it (see that here), I should probably do something about fixing these rough edges. This was the list:
Improvement 1:
Update the model:
Annoyingly the interface between Claude versions has changed, so some faffing around is needed here.
Improvement 2:
Use Prompt Manager:
What it says on the tin. No more dodgy DynamoDB table for the prompts, use the service properly.
Improvement 3:
Fix the bad loop:
Take the loop through the prompts out of a single lambda, and run them all as single Lambda’s, called using a Map state.
This also solves for speed, as the prompts are the second slowest part of the workflow
Improvement 4:
Less fragility:
Through the judicious use of “ignoring errors”, we want to be able to run all the prompts and get outputs, even if one (or most) of them fail.
Improvement 5:
File conversion result in Slack
Still using SNS -> email, but now we’re checking for the conversion job, creating an S3 pre-signed URL and sending that to the SNS topic as soon as it’s available. The pre-signed URL lasts for a couple of hours.
Yes yes, Show us a picture:
Fine, something like this:
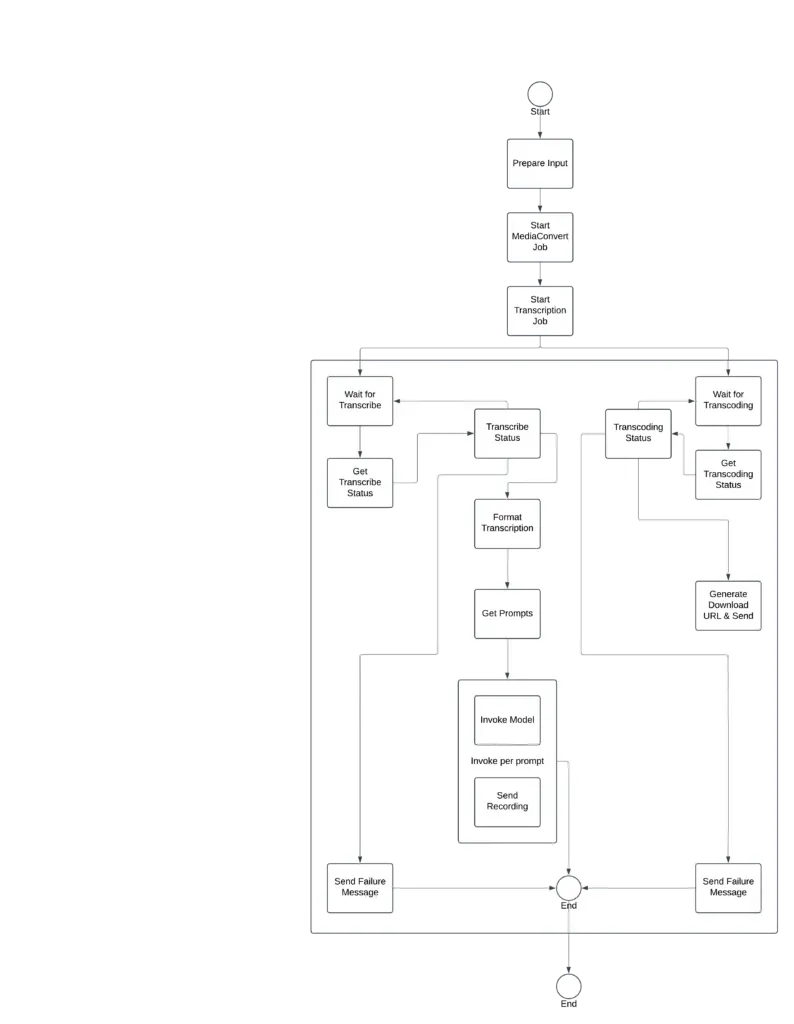
Serverless AI Workflow V2 design
Did it work?
Well, no. Not quite.
With the improvement list as a starting place, I ended up here:
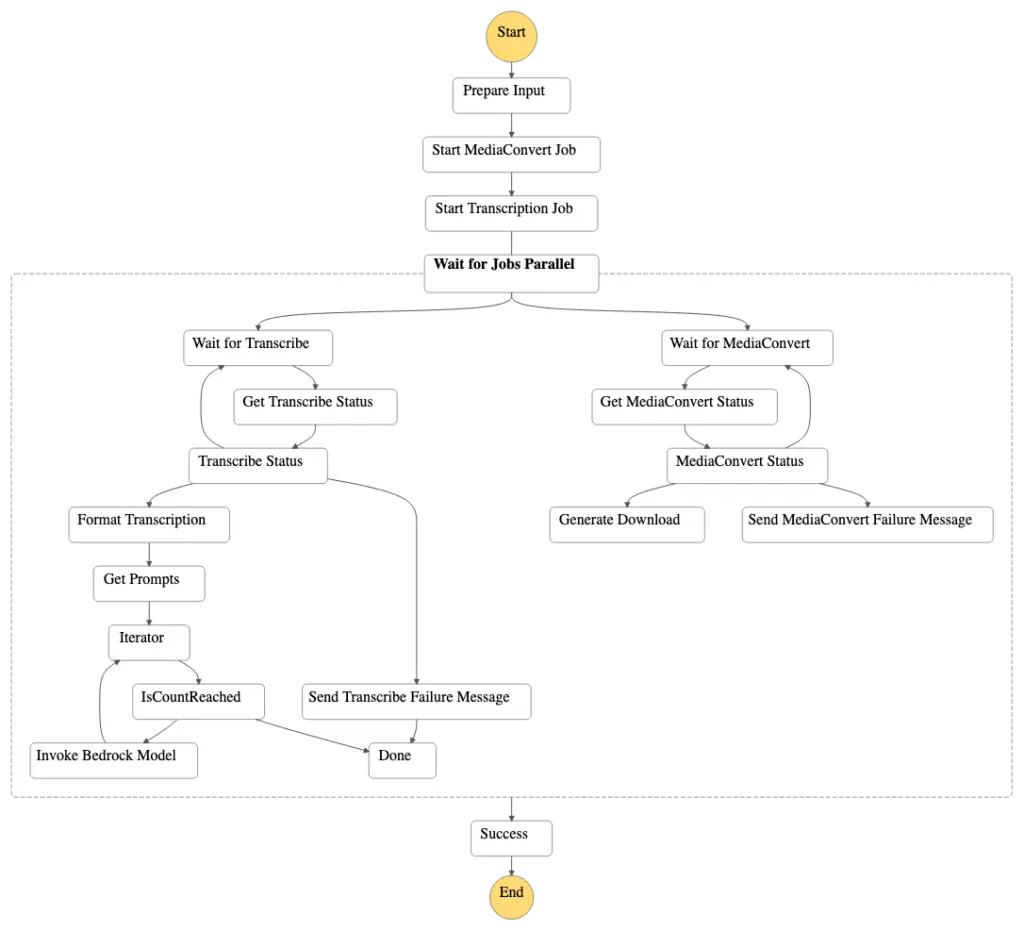
Serverless AI Workflow V2
Bigger and scarier than before I know, but it can’t be helped – we’re just doing more stuff now.
Let me walk you through it.
Steps 1-3: Kick Off:
All still the same – kick off with the upload of the m4a file, trigger the transcoding & transcription.
Only slight tweak is the transcoding trigger actually returns the job id, so I can use that later.
Step 4: Parallel State:
Now we actually use the parallel container I built earlier and split into two branches – one for the transcription & LLM invocations, and the other for the transcoding.
Step 5 (Transcoding Branch):
Nothing massively clever here, just a loop in the step function based on an if/else/continue premise to check for the status of the transcoding job.
If it’s not done, loop around again and wait some more, if it failed, if it’s completed generate a pre-signed url and send to SNS, if it failed send an error to SNS but don’t halt the step function.
This last bit is important – as far as possible we’re not halting the step function for errors in the process, especially on the lower-value task.
Step 5 (LLM Branch):
Now we grab the prompts in their own Lambda, but they’re still from DynamoDB, because I couldn’t fathom prompt manager in the few evenings I had to spend on this.
Same goes for the direct SDK integration between DDB & Step Functions really.
I’m sure some of the Serverless DevAdvocates, AWS Heroes & Community Builders I know would dislike me for this, but I didn’t see the benefit of it here.
Using Lambda Powertools in Python, grabbing the list is 4 lines of code. Plus I’d already written said code in v1, so I kept it.
Step 6 (LLM Branch):
Much the same as before, but with another loop – not a map state.
It turns out the rate limiting wasn’t because Claude v2 is ancient. It’s because all of Bedrock has really low rate limits.
This means that we’re not solving for speed, but we are solving for rate limits, with an unlimited number of prompts, so that’s something.
On each execution of the “Invoke Bedrock Model” lambda we’re dropping the prompt we ran from the list of them, as a quick-and-dirty for loop. With some time this could be cleaned up a bit, but for now it works.
Also, we’re using Claude 3.5 Sonnet V1, and have designs on both V2 (or V3.5 Opus when that eventually comes out), and Amazon Nova Pro, as the outputs in the console looked encouraging.
Step 7 (LLM Branch):
You’ll notice that a couple of states have been removed, namely the direct SDK integration with SNS for sending the results, and the “end error” state.
This reduces the re-run cost by allowing me to re-drive the state machine from the point of error in the case of hitting a rate limit – which was 90% of our errors in v1.
Step 8 (LLM Branch):
Back around to the iterator we go, but this time with an arbitrary 2 minute sleep.
This gets us around the 1 invocation-per-minute rate we’re working with, but I could do something a bit smarter here with error code checking & exponential backoff.
The iterator is well-trodden at this point – just check if the prompts list still has prompts in it, and go around again. If it’s now empty, finish the branch.
Step 9 (Both Branches):
End.
Both branches are now done, so we close out.
So, how is this better?
Well for one I don’t have to sit and wait for the transcoding to finish. The pre-signed URL is dropped straight into Slack for me to grab, so that’s nice.
Also, we can run an unlimited number of prompts, and shouldn’t get rate-limited anywhere near as often – if we do, re-drive from failure covers the restart without having to re-do the expensive transcoding & transcribing.
The updated model performs loads better, and because the interface for all Claude v3/3.5 models is the same, I have a route to make each prompt run under a different model – which I thought was the idea behind Bedrock to start with, but seems to be harder than I thought it would be.
Also we have monitoring, sort of.
I put a small Cloudwatch Alarm on the failures of the step function (well, I had Q Developer write it actually, can’t avoid using AI in this project), which also sends to the same SNS topic. That way I can just upload the file to S3, and get on with other things, without having to babysit the workflow.
And of course I have an update on the project I can write a talk for, so I best start shopping that around local meetup groups I guess.
What’s Next?
Expand the Iterator
I still want to be able to run a different model for each prompt, because models aren’t one-size-fits-all, and I’d like an easy way to test lots of different models on the same prompt.
Use Prompt Manager
Still not using this, and I really should be.
Resiliency
We’re in a better place than we were, but it’s still not as good as I’d like it to be. Ideally we’ll handle rate limit exceptions via a retry and exponential backoff, plus have proper alerting rather than a single alert for the whole Step Function.
Finally, What did we learn?
Rather a lot, as it happens.
Time & Effort Needed
Phase 1 showed the sheer amount of effort needed to get these things going, even with a big jumping-off point from AWS. This is compounded by the fact that this is a marketing/hobby project, so doesn’t get a lot of time spent on it. Phase 2 just compounded that lesson – it took the best part of a day to make the change, split across several evenings, and it’s not that different from phase 1.
Pace of Change
The pace of change within LLMs is really high – between v1 & v2 there were 6 different models released just for Claude, so keeping up with the current models is a challenge all by itself. Once you start thinking about other model providers (looking at you Amazon Nova), it’s a whole different challenge.
LLMs are Non-Deterministic
So we knew that already from the documentation, but in practice it can be really frustrating to not have a consistent output between executions, and you need to be aware of it when developing against them.
Skillset
By day I’m an SRE/Platform Engineer/Generalist Cloud Engineer, not a developer and certainly not an AI/LLM expert, so this was a challenge both dusting off my Serverless developer skills whilst learning how to interface with Bedrock. Fortunately AWS have done a really good job of making it an easy service to consume, and I highly recommend you start with the chat interface in the console to test your prompts.
The other recommendation I’d have for you is to dive in – after v1 I gravitated much more towards AI/LLM talks and workshops at the various AWS conferences I’ve attended this year (London Summit, London Partner Summit, Re:Invent), which I got much more out of for having a baseline level of knowledge, thanks to this project.
LLMs Have Rate Limits
Well, yes, you might say. However I didn’t appreciate just how low they are in Bedrock.
When you think about it, it makes sense, and our usage puts a very high number of tokens through the model in a short space of time. But you do need to be aware of them, and handle them appropriately in your own implementations.
So, What are My Tips?
Hopefully you can learn from my mistakes here, but if you want to short-circuit this whole “learning by doing” thing, I’d recommend:
- Go to a couple of workshops before getting going.
They don’t have to be in-person, and could be watching something on YouTube after-the-fact, but for a good portion of phase 1 I struggled with just understanding the new terminology I needed - Test your prompts
I said this above but it bears repeating – use the console to test your prompts and see what sort of output you’re likely to get. It’s much cheaper to do this than run a whole transcription & transcoding workflow for the sake of changing a single prompt. - Try to do model evaluation
I didn’t do this, because the project I based on had already done it, and settled on Claude2. I regret not going through the process to get a better understanding of why Claude2 was the correct choice at the time though. You’ll also learn a lot about the various models in the process, which might be useful for another project. - Request model access up front
The “non-AWS” models aren’t instantly approved when you request them, so save yourself some time and request them early. - Check the rate limits
These are different between models & regions, so you can’t assume that the same thing will work if you port it to another region - Be aware of time
If you’re new to LLM development, this is a learning curve that you’ll need to climb, so be patient with yourself. Doubly so if you’re not a developer by day. - Learn by doing
Hopefully by reading this you can go further and faster than I did, but there’s no substitute for building things when trying to learn.
To wrap this up I think I’ll quote Amazon CTO Dr. Werner Vogels:
Now, Go Build